Google’s First Machine Learning Chip (TPU) Is 30x Faster Than CPUs And GPUs

Short Bytes: At last year’s I/O, Google introduced their custom chip called Tensor Processing Unit which brought in existence to address the rising computing needs of the data centers. A paper by Google researchers compares TPU’s performance with server class Intel Haswell CPU and Nvidia GPU. It’ll be presented at the ISCA, Toronto in June.
For a company like Google which operates a gigantic pool of data centers, power friendly lightning-fast processors are a need than a luxury. That’s the reason Google already made their custom machine learning-based processor called Tensor Processing Unit (TPU).First unveiled at last year’s Google I/O with limited details, this new kind of processor breed is optimized according to Google’s TensorFlow framework.
Also Read: Microsoft Just Disclosed What Data They Secretly Collect On Windows 10
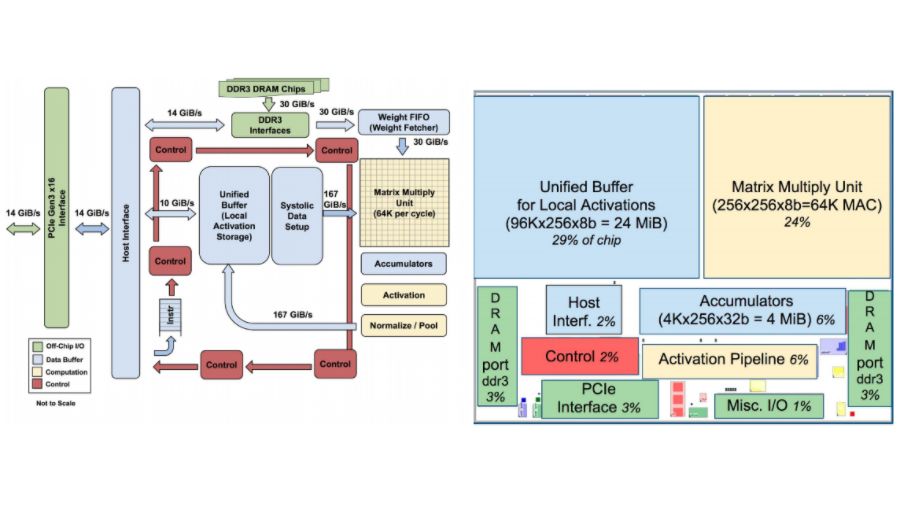
A paper published by Google researchers Norman P. Jouppi et al describes further details about the TPU. A 65,536 8-bit MAC matrix multiply unit finds its place at the TPU’s core delivering a peak throughput of 92 TeraOps (TOPS) per second. Google has done extensive benchmarking of their chip by putting it against a server-grade Intel Haswell CPU and Nvidia K80 GPU.
Google’s very own test results show that the TPU is 15x to 30x faster while handling AI workloads. TPU manifests a great level of energy efficiency by delivering 30x to 80x higher TeraOps/watt, with a possibility of increasing it further by using the faster GDDR5 memory.
The TPUs were first thought of in 2006, when Google started putting GPUs, FPGAs, and customs ASICs in their data centers (that’s what a TPU is made up of). At that time, there weren’t many applications needing special hardware, even if required, the data centers had it in excess. It was in 2013 when deep neural nets started to build popularity.
“The conversation changed in 2013 when we projected that DNNs could become so popular that they might double computation demands on our data centers, which would be very expensive to satisfy with conventional CPUs,” writes Google in their paper.
Google says they are already running TPUs in their servers since 2015. And it has helped them reduce computational expense incurred in the case of the deep learning models they previously used. In earlier cases, people using Google voice search for just three minutes per day would require deep neural nets to be run for the speech recognition system on their processing units. Google would have to double the number of their data centers.
TPUs are now powering various Google products like Image Search, Photos, Google Cloud Vision, etc. They also contributed to the drastic development made to Google Translate last year and also helped DeepMind’s AI become a Go champion.
Read the paper to know more about the Tensor Processing Unit.
If you have something to add, drop your thoughts and feedback.
Also Read: New Twitter Lite App Saves 70% Data And Loads 30% Faster, No Installation Required