SEO Tip: To Slash Or Not To Slash At The End Of A URL

Short Bytes: Traditionally the URL ending with a slash denoted a directory presence at the path, and a non-slashed version implied a file. Today, it’s a good practice that both the versions of a URL produces same content. But returning the same content for both versions can hurt SEO. Smart and proper redirection from one version to another is the key to SEO.
You might have often found yourself wondering why a particular URL wouldn’t open with a slash at the end of it or vice versa (I have). Like for example, if you visit the following URL, you’ll find a blog post —https://gdad-s-river.github.io/blog/movies-in-2017
But, if you open a URL (without slash at the end) as below, you’ll get a 404 not found error.
https://gdad-s-river.github.io/blog/movies-in-2017/
So, I set out to find:
To Slash or not to slash
Historically, URLs with a trailing slash denoted the existence of a directory at the path, and those without a trailing slash to indicate a file. For example, if you visit.
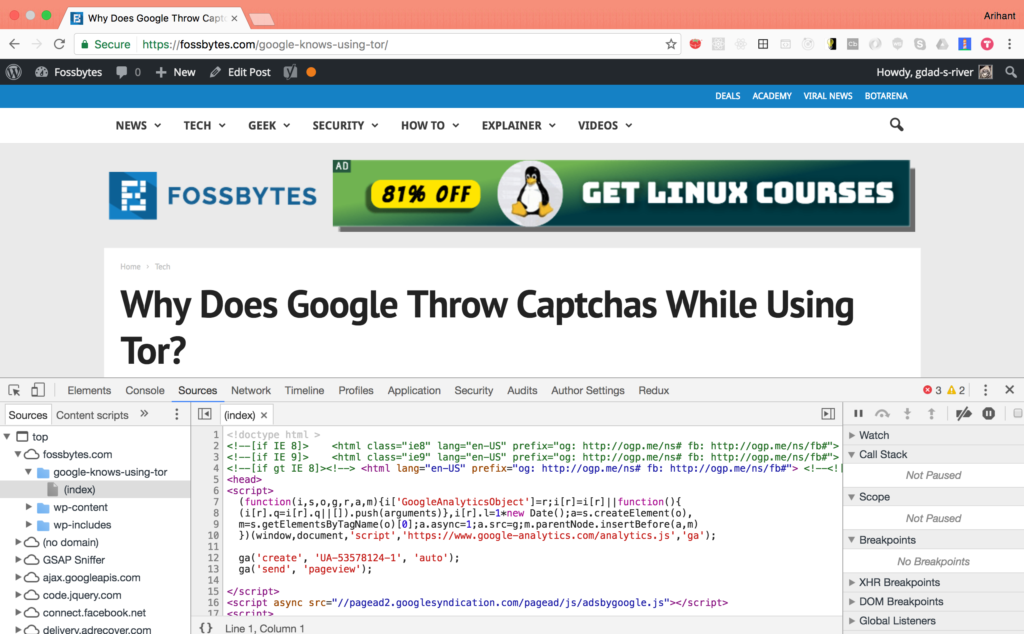
Why Does Google Throw Captchas While Using Tor?
You’ll see that the URL ends with a ‘/.’ That means there is a directory at that path, from which the default file ( index.html is served by most servers if a particular file is not configured to be served from that directory path) is served. Let’s open our browser developer tools (F12 on linux/pc, ⌘ + ⌥ + i on macOS, I’m using Chrome), and open the sources panel:
But today, both with and without slash URLs don’t have to mean so. Google treats each URL separately (and equally) regardless of whether it’s a file or directory, or it contains a trailing slash, or it doesn’t include a trailing slash.
Technically, it is possible and certainly permissible for these two URL versions to provide different content. Users, however, would go bonkers over why it is so. It would be horribly confusing for them. Just imagine two different URLs, as shown below, producing two separate content and experiences.
https://fossbytes.com/google-knows-using-tor/
https://fossbytes.com/google-knows-using-tor
Crazy!
For this reason, both versions of the URLs often serve the same content (and they should but with some things and techniques in the mind).
As a site owner/developer, what are the options that you have?
Make sure that both versions of the URLs don’t return 200 response code but that one redirects to the other. The advantage of this is that it reduces duplicate content. In case of these redirect from say https://example.com/abc to https://example.com/abc/ i.e. a redirect to trailing slash URL, the Google search result will most likely show the version of the URL with 200 response code. 200 response code is server response code or “the page has been found and sent to the client without any errors”), regardless of what type of redirect it was (301 or 302).
If both slash and nonslash versions of URL return 200 status with the same content, one can consider changing the behavior to reduce duplicate content and improve crawl efficiency. Again one can use a redirect, or add a rel=”canonical” link tag, which tells search engines that the preferred location of this URL is with the slash at the end.
<link rel="canonical" href="https://example.com/abc.html/"/>
WordPress uses this very technique. If I visit
https://fossbytes.com/google-knows-using-tor
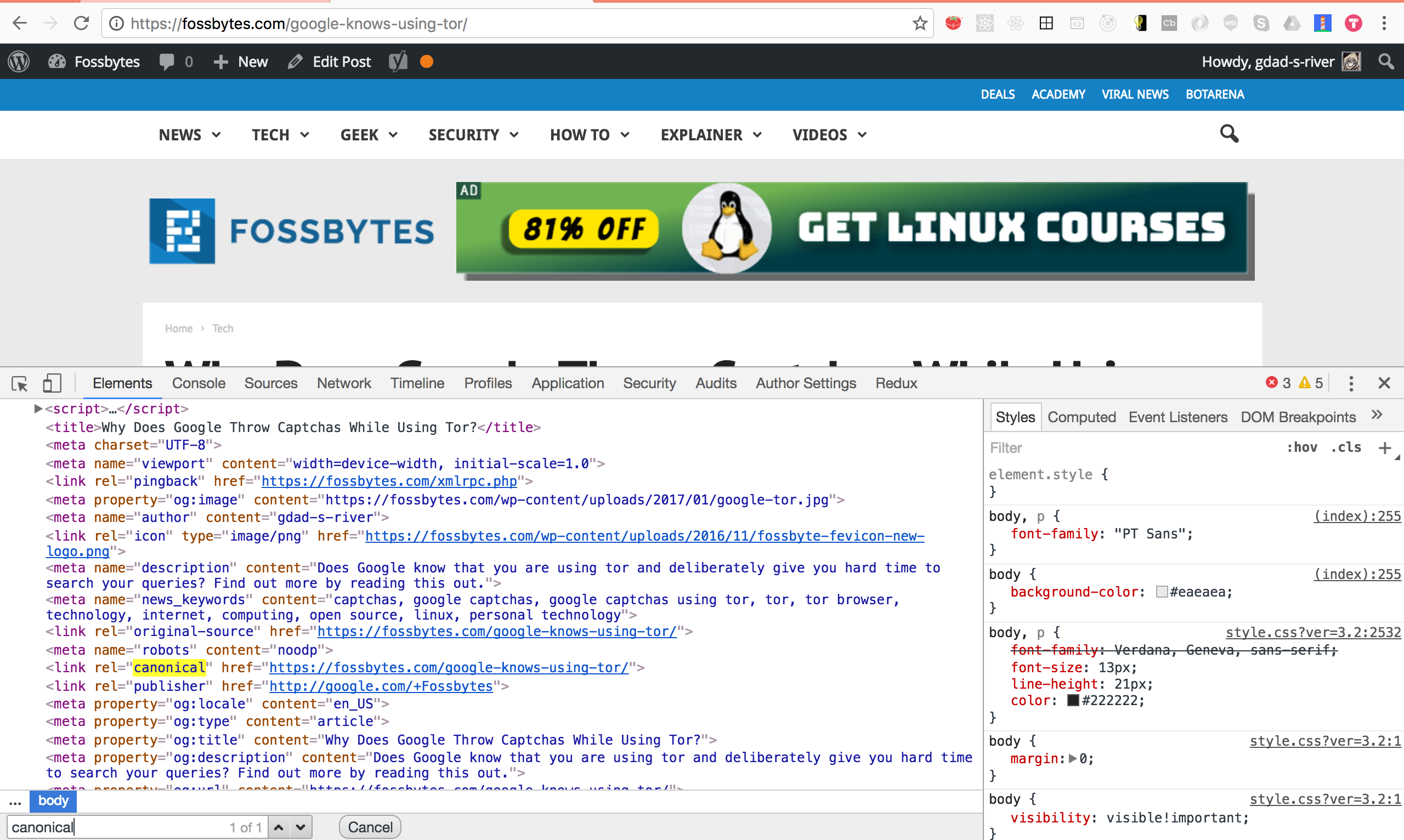
Because of the rel=”canonical” link tag, it’s redirected to the slashed URL.
Or, you can add sitemap file in your directory structure to tell the Googlebot or other crawlers how your website is structured. Sitemap can also provide essential metadata associated with your pages. In your sitemap file, do not include the duplicate URL, as simple as that.
You can test how the two version of the URL are behaving by using fetch as Google tool. In fetch as Google tool, make sure that, for example,
https://example.com/abc/
is returning 200 HTTP request status and
https://example.com/abc
is returning a 301 redirect HTTP request status to the preferred (former) URL.
Happy SEO-ing!
Let us know if this was useful information for you in the comments below. We’d love to hear from you.
Also Read: 10 Highest-Paying Jobs That Don’t Want Your College Degree