How to Build a Basic Web Crawler in Python
 Short Bytes: Web crawler is a program that browses the Internet (World Wide Web) in a predetermined, configurable and automated manner and performs given action on crawled content. Search engines like Google and Yahoo use spidering as a means of providing up-to-date data.
Short Bytes: Web crawler is a program that browses the Internet (World Wide Web) in a predetermined, configurable and automated manner and performs given action on crawled content. Search engines like Google and Yahoo use spidering as a means of providing up-to-date data.
Webhose.io, a company which provides direct access to live data from hundreds of thousands of forums, news and blogs, on Aug 12, 2015, posted the articles describing a tiny, multi-threaded web crawler written in python. This python web crawler is capable of crawling the entire web for you. Ran Geva, the author of this tiny python web crawler says that:
The python based multi-threaded crawler is pretty simple and very fast. It is capable of detecting and eliminating duplicate links and saving both source and link which can later be used in finding inbound and outbound links for calculating page rank. It is completely free and the code is listed below:
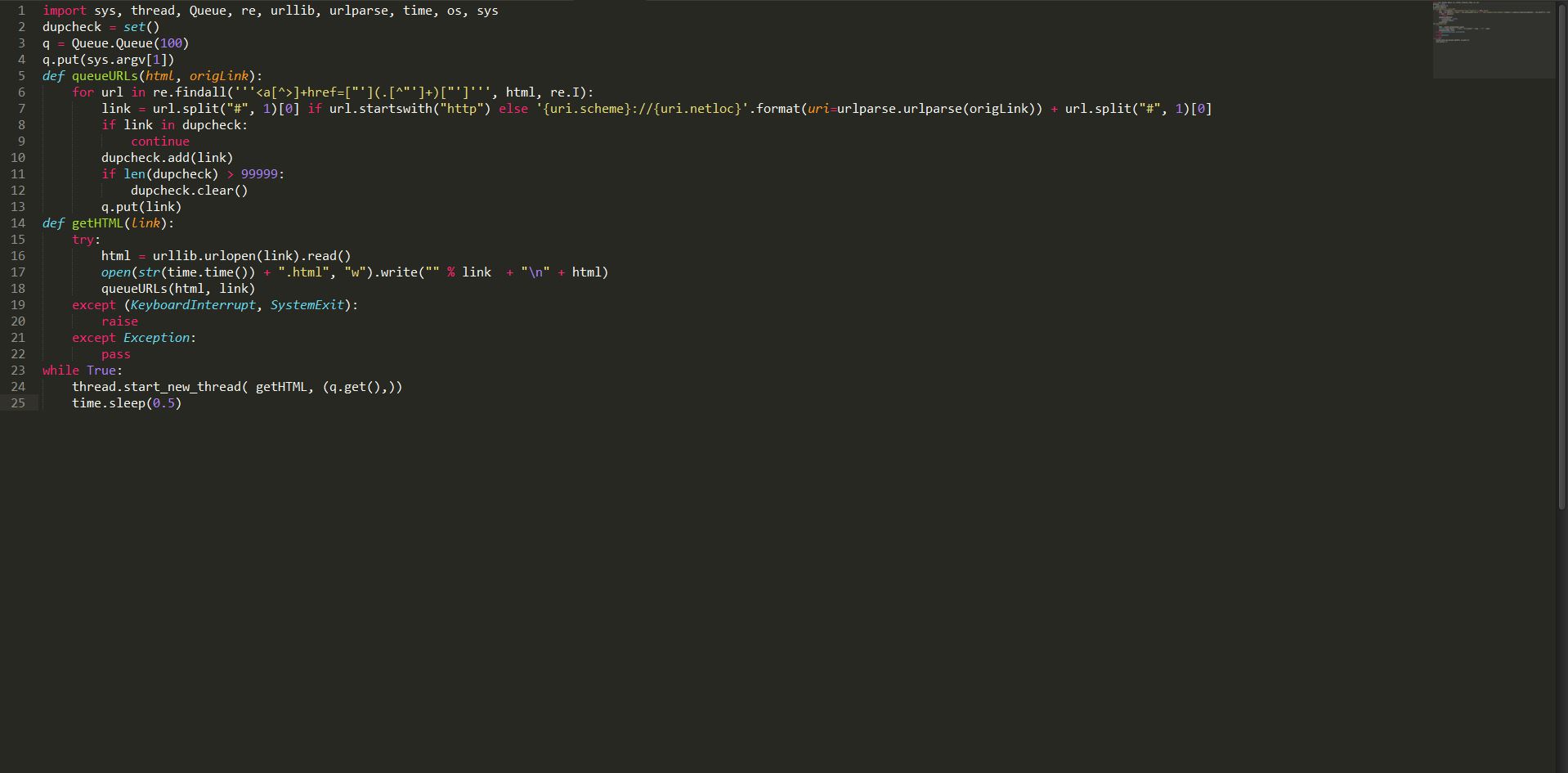
import sys, thread, Queue, re, urllib, urlparse, time, os, sys
dupcheck = set()
q = Queue.Queue(100)
q.put(sys.argv[1])
def queueURLs(html, origLink):
for url in re.findall('''<a[^>]+href=["'](.[^"']+)["']''', html, re.I):
link = url.split("#", 1)[0] if url.startswith("http") else '{uri.scheme}://{uri.netloc}'.format(uri=urlparse.urlparse(origLink)) + url.split("#", 1)[0]
if link in dupcheck:
continue
dupcheck.add(link)
if len(dupcheck) > 99999:
dupcheck.clear()
q.put(link)
def getHTML(link):
try:
html = urllib.urlopen(link).read()
open(str(time.time()) + ".html", "w").write("" % link + "\n" + html)
queueURLs(html, link)
except (KeyboardInterrupt, SystemExit):
raise
except Exception:
pass
while True:
thread.start_new_thread( getHTML, (q.get(),))
time.sleep(0.5)
Save the above code with some name lets say “myPythonCrawler.py”. To start crawling any website just type:
$ python myPythonCrawler.py https://fossbytes.com
Sit back and enjoy this web crawler in python. It will download the entire site for you.
Become a Pro in Python With These Courses
Do you like this dead simple python based multi-threaded web crawler? Let us know in comments.
Also Read: How To Create Bootable USB Without Any Software In Windows 10





