Google Imagen Is The Latest AI That Can Create Images From Text

Google has unveiled a brand new Al called Google Imagen. This AI marvel by google is a text-to-image generator. Although, it’s not yet available for the general public to use. But, the images that it can generate via simple texts are quite amazing.
Text-to-image models take text inputs like “a cat on a skateboard” and produce a relevant image. It’s something that has been done for years but recently has gotten better in quality and accessibility.
How does Google imagen work?
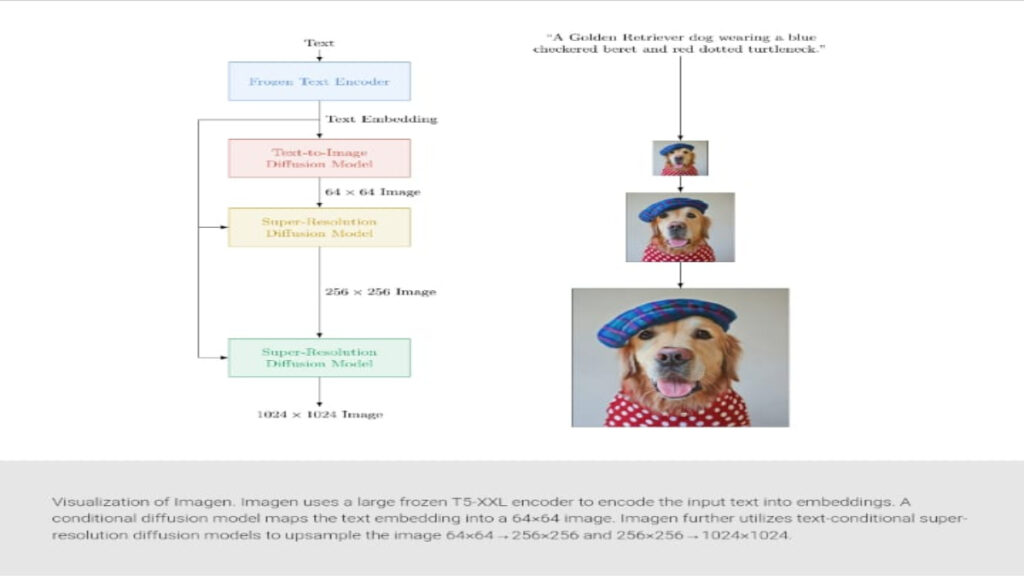
Firstly, Google Imagen uses different diffusion techniques, which basically start with a pure noise image. It slowly refines it bit by bit until the model thinks it can’t make it look any more like a cat on a skateboard than it already does.
This is an improvement over top-to-bottom generators that sometimes get it tremendously wrong on their first guess. The other element is improved language understanding through large language models. It’s done by using the transformer approach. A few other recent advances have led to convincing language models like GPT-3 and others.
The technical aspects work something like this:
Google Imagen starts by generating a small (64×64 pixels) image and then does two “super-resolution” passes on it to bring it up to 1024×1024. This isn’t like normal upscaling, though, as AI creates new details with the smaller image, using the original as a base.
The AI has an understanding of simpler objects and how do they look like. For instance, generating details in a cat’s eye is going to be an easy feat as the model has been trained to fill in tiny details.
Why is it not public yet?
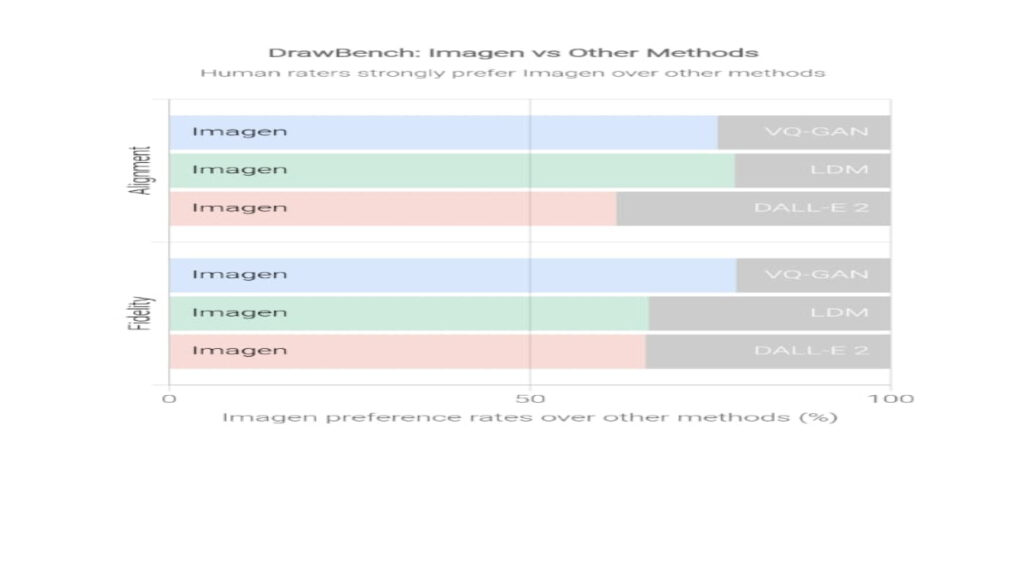
While announcing the new AI model, the company shared a research paper detailing quite a lot. It shows the use of a benchmarking tool called Drawbench to draw objective comparisons with Imagen’s competitors.
It contains a lot of hilarious images for you to draw conclusions on. Although Google imagen looks quite harmless, the paper sheds some light on its “hostility”. Google says that the AI models encode “several social biases and stereotypes, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes”.
Google could always filter out specific words or phrases and feed useful datasets. However, given the volume of data handled by these devices, not everything can be filtered through or all faults ironed out.
Since the enormous scale data requirements of text-to-image algorithms have prompted academics to rely significantly on large, mostly uncurated, web-scraped datasets,” Google acknowledges.
These datasets tend to represent societal prejudices, oppressive perspectives, and disparaging or otherwise detrimental to minority identity groups, according to dataset audits.
Keeping everything in mind google says that Imagen is not yet ready for public use. What are your thoughts on imagen? Would you like to use it? Comment down below.




