Google’s New AI Tech Can Recognize Different Voices In A Crowd

We, humans, often face a hard time distinguishing a particular voice in a gathering of people. Imagine how difficult it is for a microphone to identify distinct sounds and this is observed in cases where a smart speaker is given instructions at house parties or crowded places.
But it seems like humans are about to lose their supremacy when it comes to speech recognition. A new technology created by Google will now help its AI to pick up different voices when spoken simultaneously.
This path-breaking development in the field of speech recognition will now enable AI based virtual assistants to identify a particular voice in the crowd and comprehend it successfully.
On Wednesday, researchers at Google unveiled this incredible yet simultaneous terrifying technology. The team had been working for a long time on isolating sources of audio like speech in videos, something which automated systems have difficulty with.
How does Google’s new speech recognition AI work?
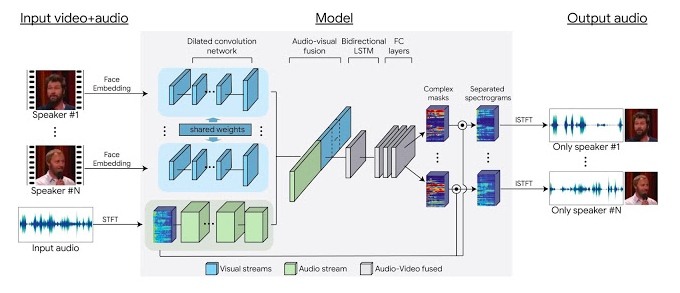
The system works on an Audio-Visual Speech Separation Model that can identify voices by monitoring people’s faces when they speak. Its neural network model was trained to pick out sounds from different individuals through ‘fake parties’ created by the researchers.
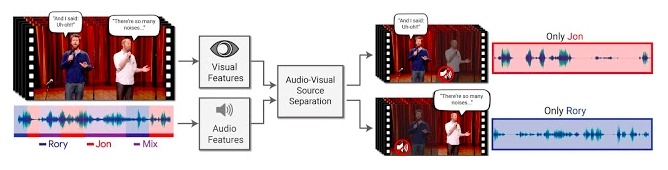
Background noises were mixed in these virtual parties in order to teach the AI how to distinct audio tracks by isolating multiple voices. The results were mindblowing as the system could entirely separate not just the noise but also the speech of two people talking simultaneously.
However, the privacy implications of Google’s new speech recognition technology are quite scary. If implemented a large scale, this system could be used by third parties to spy on people by listening to their speech. Although it would require far greater improvements to accomplish it, such a future might not be far off.
Also Read: Researchers Create An AI System That Thinks Like A Dog