Deep Learning Program Creates 3D Face Models From Your Selfie — Try It Here
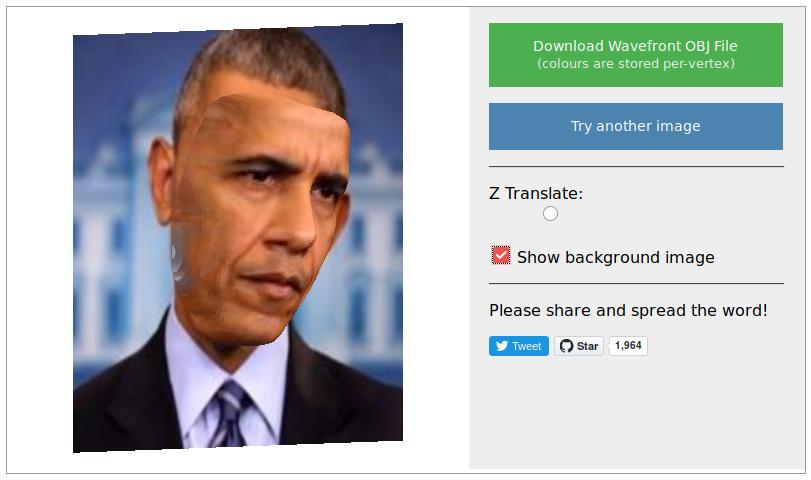
Researchers from the University of Nottingham and Kingston University have developed a direct method for reconstructing the 3D depth information from a single 2D facial image. This method, which works on any 2D face, is the first step in generating 3D selfies. It is only a matter of time until this model makes its way into our smartphones.
The idea of 3D selfies has been around for quite some time — constructing the 3D model of your face. Sure, one can use Microsoft Kinect’s 3D depth sensor to scan the face and construct a 3D model out of it. But the problem that the computer scientists of University of Nottingham and Kingston University attempted to solve is a different one — to reconstruct the 3D image from a single 2D input image. This problem is not a trivial one — in fact, it had remained unsolved for a long time.
The general problem of reconstruction is more like filling up the blanks — given information in some form, the task is to generate new information from it, or more specifically, to recover the hidden information that was lost while obtaining the first kind of information. For example, when we take selfies, the 3D depth information of our face is lost; In Black and White photography, both the depth and colour information are lost; In out-of-focus/blurred images, the shape information of the object is lost.
Researchers, led by Aaron Jackson, a PhD student from the University of Nottingham, have developed a new kind of Convolutional Neural Network(CNN) called as Volumetric Regression Network(VRN). The VRN, nicknamed as hourglass network, essentially maps each facial feature from the 2D image to a 3D vertex. The VRN model takes in a 2D colour image of a face and outputs a 3D volume from which the outermost facial mesh is recovered. You can try the demo here.

They trained this mode with a dataset of over 60,000 2D-3D image pairs so that the model learns to map the common facial features, and therefore works on any given input face. The amazing feature is that this model can reconstruct the 3D facial geometric even for the non-visible parts of the face. This is an important breakthrough, especially for VR and AR applications.
As is the norm of Deep Learning research, the authors have open sourced their code in Github. But before probing into their code, watch their results in action here. Remember how Barack Obama’s face was 3D scanned using 50 custom LED lights and 8 GoPro cameras? This research can make it with a few snapshots of his face from his public appearances.
So, what applications can you think of from this cool research? Share your thoughts with us.
Also Read: Caffe2 : The Deep Learning Framework for Mobile Computing