How Search Engine Works and Makes Your Life Easier?

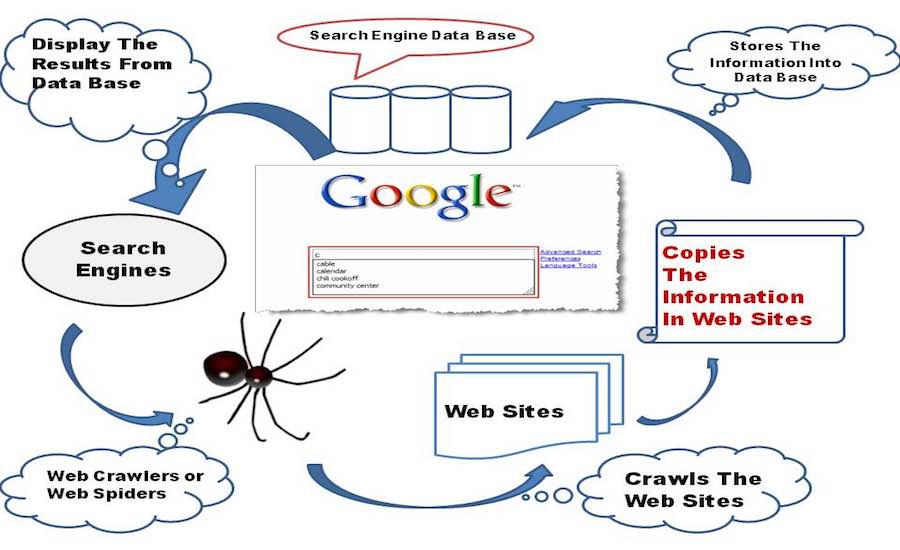 Short Bytes: Search Engine is a software that allows the display of relevant webpage results based on the search query input by the use of Web Crawling and Web Indexing, some fat formulae and intelligent algorithms in order to gather the appropriate data.
Short Bytes: Search Engine is a software that allows the display of relevant webpage results based on the search query input by the use of Web Crawling and Web Indexing, some fat formulae and intelligent algorithms in order to gather the appropriate data.
How Google serves you the best results at a blink of an eye? Actually, it doesn’t matter until Google, Bing are there. The scenario would’ve been very different if there was no Google, Bing, or Yahoo. Let us dive into the world of search engines and see, how a search engine works.
Peeping into the history
The search engine fairy tale began in 1990s when Tim Berners-Lee used to enlist every new webserver which went online, to the list maintained by the CERN webserver. Until September, 93, no search engines existed on the internet but only a few tools which were capable of maintaining a database of file names. Archie, Veronica, Jughead were the very first entrants in this category.
Oscar Nierstrasz from the University of Geneva is accredited for the very first search engine that came into existence, named W3Catalog. He did some serious Perl scripting and finally came out with the world’s first search engine on September 3, 1993. Furthermore, the year 1993 saw the advent of many other search engines. JumpStation by Jonathon Fletcher, AliWeb, WWW Worm, etc. Yahoo! was launched in 1995 as web-directory, but it started using Inktomi’s engine search from 2000 and then shifted to Microsoft’s Bing in 2009.
Now, talking about the name which is the prime synonym for the term search engine, Google Search, was a research project for two Stanford graduates, Larry Page and Sergy Brin, having its initial foot prints in March, 1995. Google’s working was initially inspired by Page’s back-linking method which did calculations based on how many backlinks originated from a webpage, so as to measure the importance of that page in the World Wide Web. “The best advice I ever got”, Page said, while he recalled, how his supervisor Terry Winograd supported his idea. And since then, Google never looked back.
It all begins with a crawl
A baby search engine in its nascent stage begins exploring the World Wide Web, with its small hands and knees it explores every other link it finds on a webpage and stores them in its database.
Now, let’s focus on some behind the scene technical thoughts, a search engine incorporates a Web Crawler software which is basically an internet bot assigned the task to open all the hyperlinks present on a webpage and create a database of text and metadata from all the links. It begins with an initial set of links to visit, called Seeds. As soon as it proceeds with visiting those links, adds new links in the existing list of URLs to visit, known as Crawl Frontier.
As the Crawler traverses through the links, it downloads the information from those web pages to be viewed later in the form of snapshots, as downloading the whole webpage would require a whole lot of data, and it comes at a pocket burning price, atleast in countries like India. And I can bet, if Google was founded in India, all their money would be used to pay the internet bills. Hopefully, that’s not a topic of concern as of now.
The Web crawler explores the web pages based on some policies:
Selection Policy: Crawler decides which pages it should download and which it shouldn’t. The selection policy focuses on downloading the most relevant content of a web page rather than some unimportant data.
Re-Visit Policy: Crawler schedules the time when it should re-open the web pages and edit the changes in its database, thanks to the dynamic nature of the internet which makes it very hard for the Crawlers to remain updated with the latest versions of the webpages.
Parallelization Policy: Crawlers use multiple processes at once to explore the links known as Distributed Crawling, but sometimes there are chances that different processes may download the same web page, so the crawler maintains a co-ordination between all the processes to eliminate any chances of duplicity.
Politeness Policy: When a crawler traverses a website, it simultaneously downloads web pages from it, thus increasing the load on webserver hosting the website. Hence, a term “Crawl-Delay” is implemented in which the crawler has to wait for a few seconds after it downloads some data from a webserver, and is governed by the Politeness Policy.
Also read: How to Build a Basic Web Crawler in Python
High-level Architecture of a standard Web Crawler:
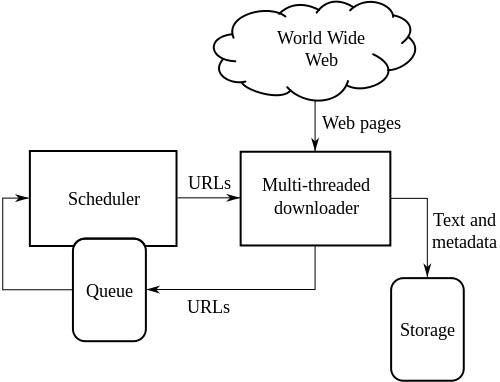
The above illustration depicts how a web crawler works. It open the initial list of links and then links inside those links and so on.
Wikipedia writes, computer science researchers Vladislav Shkapenyuk and Torsten Suel noted that:
While it is fairly easy to build a slow crawler that downloads a few pages per second for a short period of time, building a high-performance system that can download hundreds of millions of pages over several weeks presents a number of challenges in system design, I/O and network efficiency, and robustness and manageability.
Indexing the crawls
After the baby search engine crawls all over the internet, it creates an Index of all the webpages it finds in its way. Having an index is way better than wasting time finding the search query from a heap of large sized documents, it’ll save both time and resources.
There are many factors which contribute to creating an efficient indexing system for a search engine. Storage techniques used by the indexers, size of the index, the ability to quickly find the documents containing the searched keywords, etc. are the factors responsible for efficiency and reliability of an index.
One of the major obstacles in the path to making successful web indices is the collision between two processes. Say one process wants to search a document and at the same time another process wants to add a document in the index, kind of creates conflict between the two processes. The problem is more worsened by the implementation of distributed computing by the search engines in order to handle more data.
Types of Index
Forward: In these type of indices, all the keywords present in a document are stored in a list. The forward index is easy to create in the starting phase of indexing as it enables asynchronous indexers to collaborate with each other.
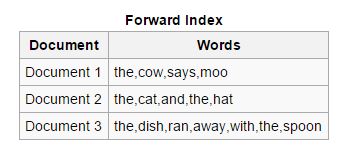
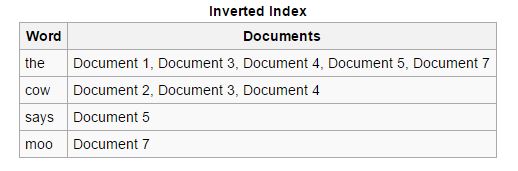
Reverse: The forward indices are sorted and converted to reverse indices, in which each document containing a specific keyword is put together with other documents containing that keyword. Reverse indices ease up the process of finding relevant documents for a given search query, which is not the case with forward indices.
Also Read: What is DNS (Domain Name System) and How it Works ?
Parsing of Documents
Also called Tokenization, refers to the breakdown of components of a document such as keywords (called tokens), images and other media, so that they can be inserted in indices later on. The method basically focuses on understanding the native language and predicting the keywords that a user might search for, which serve as the foundation for creating an effective web indexing system.
Major Challenges include finding the word boundaries of keywords to be extracted, as we can see languages like Chinese and Japanese don’t generally have whitespaces in their language scripts. Understanding the ambiguity possessed by a language is also a point of concern, as some languages start to differ slightly or even considerably with geographical changes. Also, the inefficiency of some webpages to not clearly mentioning the language used is also a matter of concern and increases the workload on the indexers.
Search engines have the ability to recognize various file formats and successfully extract data from them, and it is necessary that utmost care should be taken in these cases.
Meta Tags are also very useful in creating the indices very quickly, they reduce web indexer’s efforts and eases the need to completely parse the whole document. You’ll find Meta Tags attached at the bottom of this article.
Searching the index
Now, the baby search engine is not a baby anymore, he has learnt, how to crawl and how to grab things quickly and efficiently, and how to arrange his things systematically. Suppose, his friend asks him to find something from his arrangement, what will he do? There are four types of search queries in use, though they are not formally derived, but they have evolved over time, and have been found to sense valid in terms of real life queries made by users.
Navigational: This term is used for those queries in which the user wants to go to a specific webpage or website existing on the internet. For example, when you search fossBytes on Google, then you’re initiating a Navigational Query.
Informational: This type of queries have thousands of results and cover general topics which enhance the knowledge of the user. For example, when you search for, say Steve Jobs, you’ll be presented with all the links relevant to Steve Jobs.
Transactional: Queries focusing on user’s intent to perform a particular action, may involve a pre-defined set of instructions. For example, How to find your Lost/Stolen Laptop?
Connectivity: These type of queries are not frequently used, they focus on how connected is the index created from a website. For example, if you search, How many pages are there on Wikipedia?
Google and Bing have created some serious algorithms which are capable enough to determine the most relevant results for your query. Google claims to calculate your search results based on over 200 factors like quality of the content, new or old, safety of the webpage, and many more. They have the world’s greatest minds appointed at their Search labs, who do hard calculations and deal with mind-blowing formulae, only to make the Search more simple and quick for you.
Other notable features*
Image Search: You’ll be surprised to know Google’s inspiration behind their famous image search tool. J.Lo, yeah you heard that right, J.Lo and her green Versace(ver-sah-chay) gown at the Grammy Awards, 2000, were the real reason Google came out with its image search, as people were busy Googling about her.
Said Eric Schmidt in his writing titled,” The Tinkerer’s Apprentice”, published on January 19, 2015.
Voice Search: Google was first to introduce voice search on its search engine after a lot of hard work and subsequently other search engines have also implemented it.
Spam Fighting: Search engines deploy some serious algorithms, so that they can guard you from spam attacks. A spam is basically a message or a file that is spread all over the internet, maybe for advertisement or for transmitting viruses. In this matter also, Google guys manually inform the website they find is responsible for spreading spam messages on the internet.
Location Optimization: The search engines are now capable of displaying results based on the location of the user. If search, What’s the weather like in Bengaluru, then the weather stats will be in reference with Bengaluru.
Understands you better: Modern search engines are capable of understanding the meaning of the user query rather than finding the keywords entered by the user.
Auto-complete: The ability to predict your search query as you type based on your previous searches and searches made by other users.
Knowledge Graph: This feature, provided by Google Search, shows off its ability to provide search results based on real life people, places, and events.
Parental Control: Search engines allow parents of small kinds to control what their child has been up to on the internet.
* It is hard to cover the vast list of features provided by these mighty search engines.
Winding Up
Search engines have contributed to make our lives simpler and the hard work they’ve been doing to harness all the information on the internet is priceless. But this exploration has led to the exhibition of our personal space on a public platform, and I must say, it is high time we should fluster about the path we have been traversing all this long, unless it’s too late for us to retrospect our actions and our life only be a biennale of embarrassments. We can’t deny the fact that search engines are now a vital part of our digital split personality. We only need to make use of the technology we’ve been given, not allow it to enslave us in the chains of our own misdeeds.
Okay, no more emotional talks, just adore the cuteness and talents of that baby search engine who has now become a teenager, and understands you much better. Google has been there to search everything for us, it is the internet for many of us, and we must cherish those good experiences we’ve earned while using Google Search. Oh! I forgot to mention Bing, you’re awesome too. Stay alert, stay safe and Google it.
Watch this video and know more about search engines:
Have you ever clicked the I’m feeling Lucky button on Google Search. Open it and tell us which doodle you liked the best in the comments section below.
![Here's How You Can Perform A Factory Reset On Your PS4 [2022]](https://fossbytes.com/wp-content/uploads/2022/06/Heres-How-You-Can-Perform-A-Factory-Reset-On-Your-PS4-2022-768x432.jpg)