How To Use Column Command In Linux With 10 Examples?

The column is a very useful Linux command-line utility that can help you to view a single long list of output data in multiple columns in a terminal. With various options available for a column, you can also use it to format data and do more than just columnating it.
Let’s see how we can effectively use the Linux Column command in a terminal to stay more productive.
10 Ways To Use Column Command In Linux
1. Display Data In Column
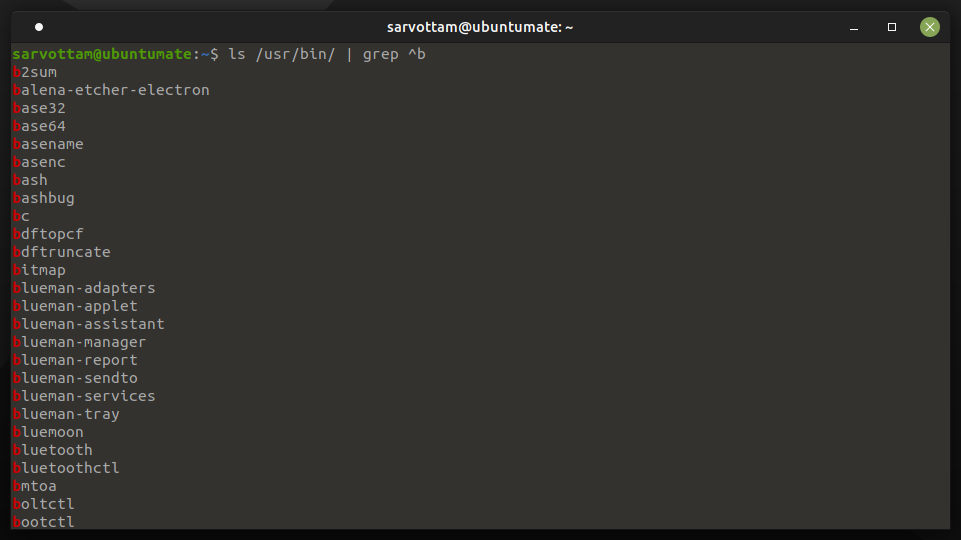
Suppose you want to list all binaries from /usr/bin/, whose name starts with b. If you run the command without using column, it will give you all output in a single column.
Now, if you pipe the output from the last command to column utility, you can see the below output.
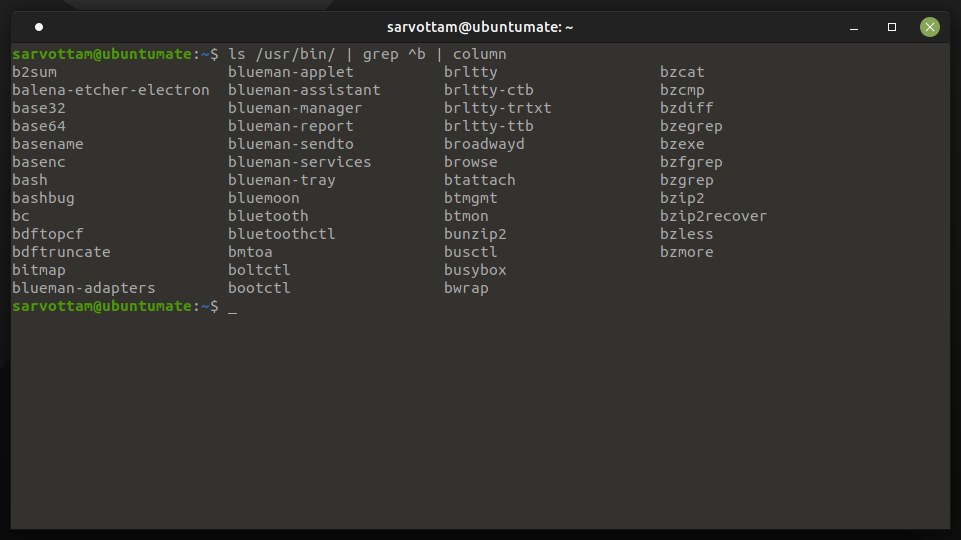
Did you see the difference column bring? Column simply distributed a single list of output into multiple columns. You can now view all output on a screen at a time without scrolling down.
If you have a long list of content in your file, then you can also use column command to display more data on a screen using the command:
$ column <filename>2. Display Data In A Tabular Form
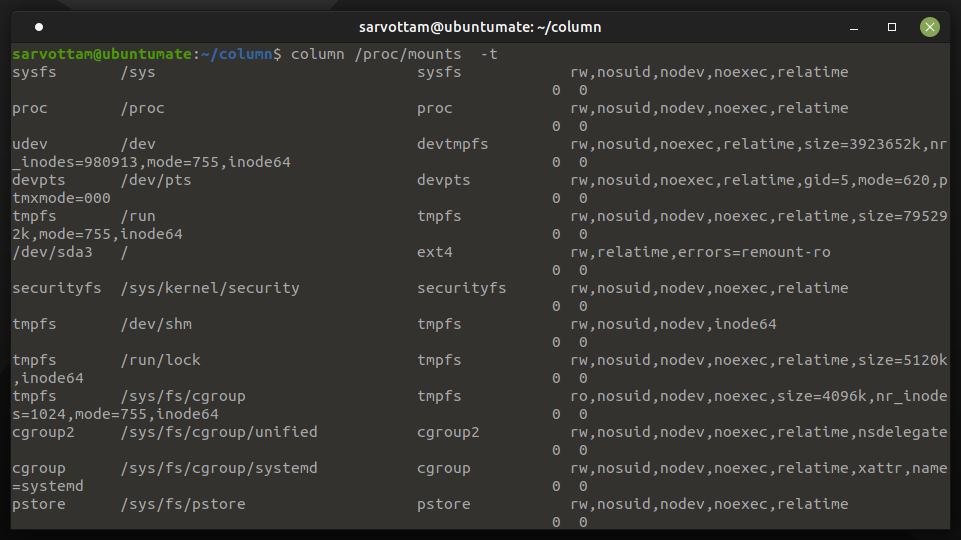
If you want a clear view of your input data in a tabular form where columns are delimited with whitespace or other characters, Column utility has a -t or --table option.
It creates a table by determining the number of columns input contains using a delimiter.
3. Delimited Output Data
Suppose you get the input data in the following form.
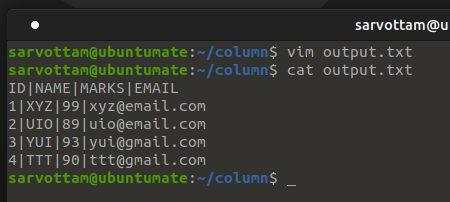
Now you want to view output data in a table form but with column separated by whitespace in place of “|” delimiter. You can use the column command’s -s or --separator option that separates the table column based on the delimiter you pass.
$ column <filename> -t -s "<delimiter>"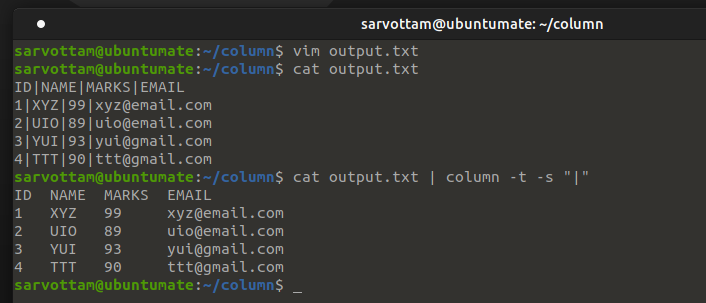
4. Output Data Separator
As you saw in the previous example, using -s option column creates a table with column separated by whitespaces. But what if you want column in the output data separated by any other character instead of the default two spaces?
For the same, Column has -o or --output-separator options that you can use to specify your column delimiter for table output.
$ column <filename> -t -s "<character-to-be-replace>" -o "<new-delimiter>"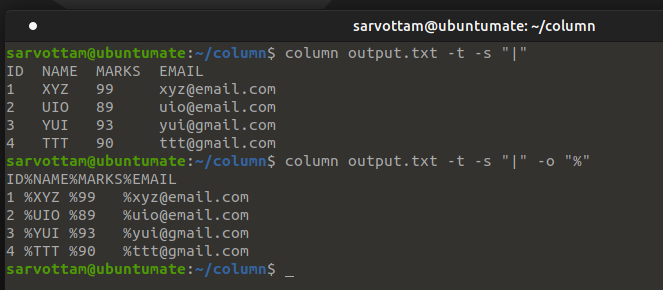
5. Output Data With Custom Column Name
Sometimes you get input data with no column name or header that specify columns in a table.
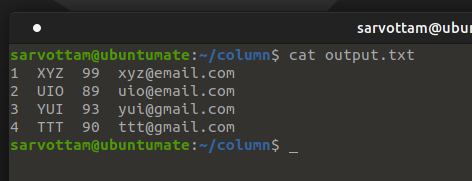
In such a case you can use -N or --table-columns option to give logical column names separated by commas in the command line. If you specify the column name for columns that do not exist in the table, a table will still make space for it.
$ column <filename> -t --table-columns <columns-names>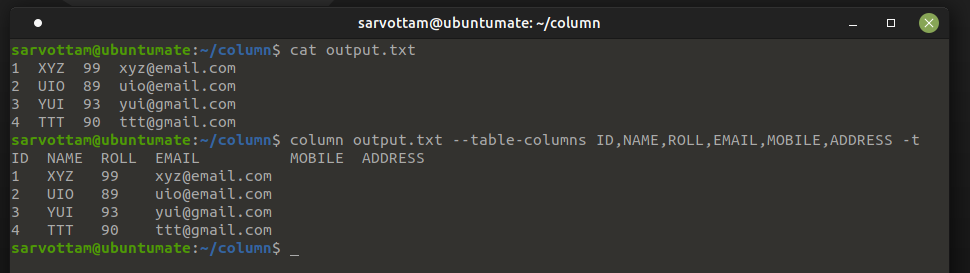
6. Display Output In JSON Format
Instead of column and table format, the Linux Column utility also provides an option -J or --json to display output in JSON format.
To print JSON output, you must need to specify column name using --table-columns.
$ column <filename> -t --json --table-columns <columns>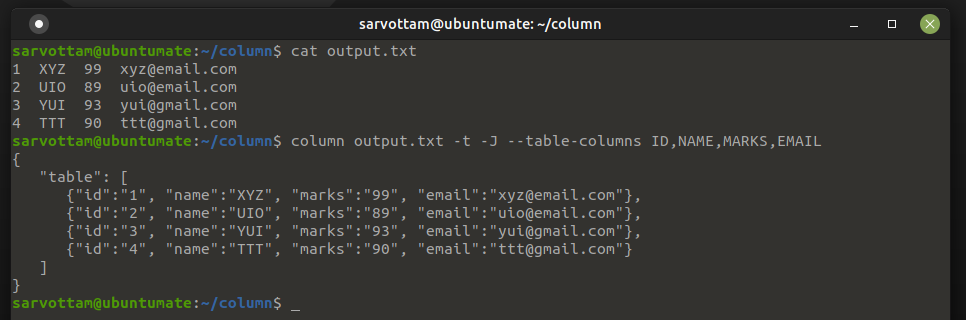
As you can see in the above picture, column command gives “table” as the default name for JSON output. Using -n or --table-name, you can also give a custom table name for it.
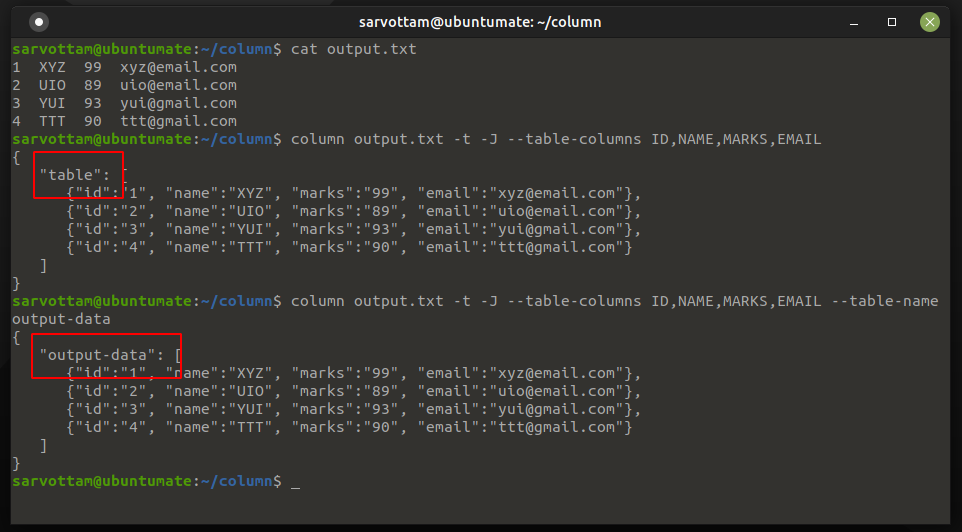
7. Change Output Orientation
By default, column print output data following the column to row mode. This means, it first fills the column before rows.

But if you want to reverse it to fill the first rows and then columns, you can use -x or --fillrows option.

8. Show Output With Empty Lines
If your input data contains an empty line with whitespace only, it is most likely that it will be ignored by column command by default.
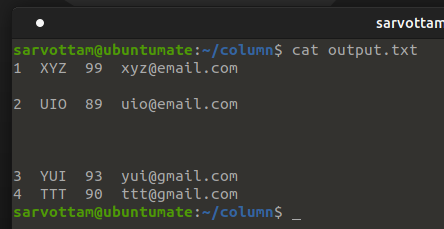
Hence, if you want to keep that lines with whitespace in the output display, you need to use -L or --table-empty-lines option.
$ column <filename> -t --table-empty-lines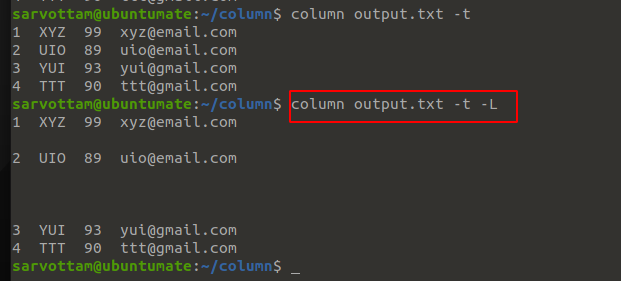
9. Reorder Column Position
If you want to reorder the column position, the Linux column command also has an option -O or --table-order to specify column order on output.
$ column <filename> -t --table-columns <columns> --table-order <reordered-columns>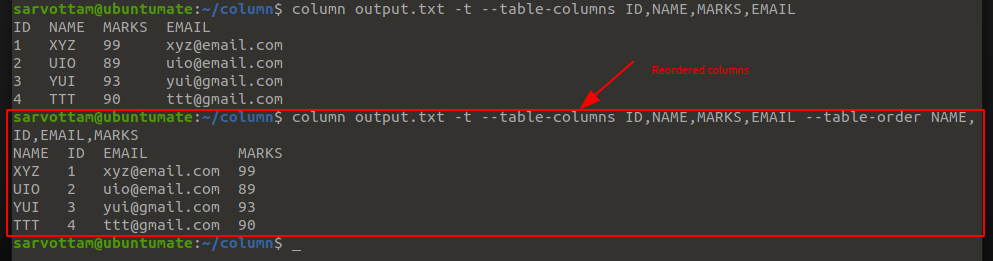
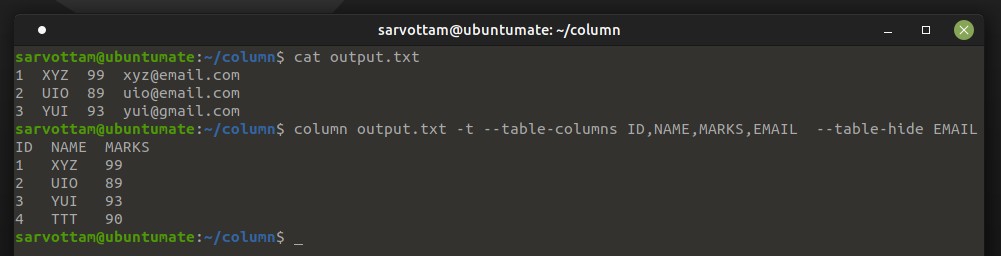
10. Hide Columns
Want to hide specified columns? you can use -H or --table-hide option with column command.